|
Indexing (Spidering)
Here are some quick answers to the most commonly asked questions about
indexing (spidering) a site.
If you don't find what you are looking for here, try the FAQs:
Too Few Pages Indexed,
Too Many Pages Indexed, and
Host/ISP-specific Issues.
TOP QUESTIONS
Why is my site no longer spidered?
This typically happens because your hosting company has moved your site.
Amazingly, this happens! Double-check the current location of your site
and make the necessary corrections.
How does the spider (indexer) find my pages?
The search engine spider starts with the web address (URL) you entered when you signed-up.
It reads all the links on that page. Those links which start with the same URL
are then read by the spider. It then looks for links on those pages that start with the same URL
as the one you signed-up with, and reads them, and so forth. Once all pages have
been read an index is built and an email is sent to you informing you of the results.
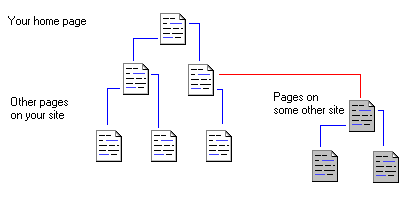
Here we see a simplified example, showing a site with six pages, and a link
to someone else's web site. The spider would start by reading your home page
and following the links to other pages on your site (blue lines).
It will not follow links to sites that are not yours (red line). In this
example pages in white will be indexed, and gray ones ignored.
MORE QUESTIONS
What parts of each page get indexed?
By default words in the following parts of each web page are included in the index:
- the title,
- the keywords meta tag,
- the description meta tag,
- the body of the page.
The spider does not index words in javascript nor in the image tag "alt" attribute.
|

